Faster than Quick[Sort]
26 Jul 2014Can a sorting algorithm outperform QuickSort?
Of course, there are a number of restricted subdomains where known algorithms consistently outperform QuickSort: Count Sort for example, is extremely performant on sets with a limited number of (non-unique) elements; Radix Sort is another good example for integers (LSD version) and strings (MSD version).
A completely different approach is used in adaptive algorithms: rather than focusing on subdomains, these approaches exploit existing order in the arrays to cut the number of comparisons and swaps needed, and they work for any kind of data: integers, strings doubles etc...
One might frown upon the benefit of such adaptive methods. Except that real life is filled with problems that involves nearly sorted sequences. Think about a time sequence where data is gathered in parallel from several sources: does incremental map reduce ring a bell? Or about a huge sorted sequence where a constant number of elements can have their keys incremented or decremented at any time: simulation environment, evolutionary algorithms, list of polygons in a mesh could be examples of such a situation.
There are a number of well known adaptive sorting algorithms that have been proven optimal for different measures of disorder [measure of presortedness] in arrays (for an example of a measure of disorder, consider the number of inversions in an array, i.e. the number of couples (i,j) such that i < j and A[i] > A[j]). The vast majority of these algorithms are targeted to improve the upper bound on the number of...
Final project for Practical Machine Learning course
23 Jul 2014Background
Using devices such as Jawbone Up, Nike FuelBand, and Fitbit it is now possible to collect a large amount of data about personal activity relatively inexpensively. These type of devices are part of the quantified self movement – a group of enthusiasts who take measurements about themselves regularly to improve their health, to find patterns in their behavior, or because they are tech geeks. One thing that people regularly do is quantify how much of a particular activity they do, but they rarely quantify how well they do it. In this project, your goal will be to use data from accelerometers on the belt, forearm, arm, and dumbell of 6 participants. They were asked to perform barbell lifts correctly and incorrectly in 5 different ways. More information is available from the website here: http://groupware.les.inf.puc-rio.br/har (see the section on the Weight Lifting Exercise Dataset).
Task
The goal of your project is to predict the manner in which they did the exercise. This is the "classe" variable in the training set. You may use any of the other variables to predict with. You should create a report describing how you built your model, how you used cross validation, what you think the expected out of sample error is, and why you made the choices you did. You will also use your prediction model to predict 20 different test cases.
My solution
First, I loaded caret package, then the data in R. There are 160 columns, so I first took...
ServiceWorker Holds Great Promise for Caching and Offline Applications
23 May 2014The ServiceWorker specification allows scripts to cache resources and handle all resource requests for an application even when a network isn't available. To put it in a different way, the ServiceWorker browser feature enables developers to build applications that work offline, overcoming the limits of HTML5 Application Cache (AppCache) by giving developers a set of primitives to handle every HTTP call on a Website, as well as controlling installation and updates for the cache rules.
Sounds cool, right? Well, it is. Interested in going in-depth? A few resources:
Be sure to check this post I have pubblished on ProgrammableWeb
The first draft of ServiceWorker spec
A detailed explaination by Alex Russell
Another great post by Jake Archibald
Karger Randomized Contraction algorithm for finding Minimum Cut in undirected Graphs
22 May 2014Karger's algorithm is a randomized algorithm to compute a minimum cut of a connected Graph. It was invented by David Karger and first published in 1993.
A cut is a set of edges that, if removed, would disconnect the Graph; a minimum cut is the smallest possible set of edges that, when removed, produce a disconnected Graph. Every minimum cut corresponds to a partitioning of the Graph vertices into two non-empty subsets, such that the edges in the cut only have their endpoints in the two different subsets.
Karger algorithm builds a cut of the graph by randomly creating these partitions, and in particular by choosing at each iteration a random edge, and contracting the graph around it: basically, merging its two endpoints in a single vertex, and updating the remaining edges, such that the self-loops introduced (like the chosen edge itself) are removed from the new Graph, and storing parallel-edges (if the algorithm chooses an edge (u,v) and both u and v have edges to a third vertex w, then the new Graph will have two edges between the new vertex z and w) After n-2 iterations, only two macro-vertex will be left, and the parallel edges between them will form the cut.
The algorithm is a Montecarlo algorithm, i.e. its running time is deterministic, but it isn't guaranteed that at every iteration the best solution will be found.
Actually the probability of finding the minimum cut in one run of the algorithm is...
You'd better stay away from the "this" trap when defining a JavaScript module
07 Mar 2014JavaScript this pointer is actually evil... especially if you are going to export modules.
Let's start with an example
function declareModuleTest () { return { funA: function funA () { console.log("A",this); }, funB: function funB () { console.log("B", this); return this.funA(); } } } var module = declareModuleTest(); function testThis (callback) { callback(); } testThis(module.funB);What is the expected outcome, in your opinion? What do you think it will be the value of this inside funB, when called from testThis? Chances are you haven't bet on "page will crash", but actually this is the case: an exception will be thrown at this line
return this.funA();because the value of this will either be null or window, depending on if you are using strict mode.
If we had called funB as module.funB(), there would have been no problem, and the execution would proceed as expected: let's see why!
A step back: The this pointer
The Internet is crammed with literature on the infamous "this" pointer. It actually is one of those bad parts highlighted by...
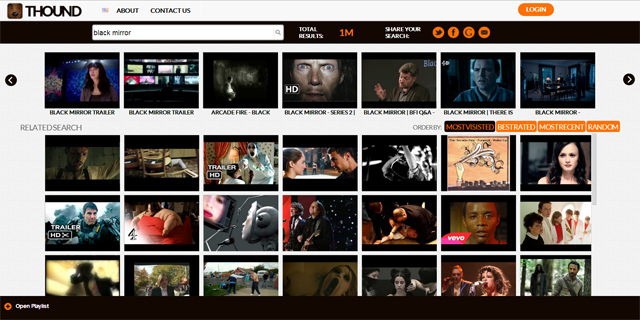
Reengineering TubeHound, a video search aggregator
15 Feb 2014AKA Considerations about choosing the right technology stack for your application.
What
A video search aggregator, is a tool that makes your life easier when you need to query online videos. There are many ways to aggregate your searches, and to help you find what you are looking for. The idea behind TubeHound is that sometimes, when you are looking for videos about a certain topic, you might as well be interested in videos which do not directly match your search, but are nonetheless connected to the ones that do. For example, when you are looking for a trailer of a certain movie, you might be interested to watch trailers of similar movies. Or, if you are looking for a tutorial by a specific content producer, say a cooking tutorial from your favourite chef, you are probably interested in acknowledging the existence of other chefs who release tutorials, and maybe, once you notice them, you might be interested in searching more results about them.
TubeHound, for every query you submit, shows you many results related to the videos matching you search terms, and allows you to refocus your search with a couple of mouse clicks: the goal is making navigation among your results as easy as following your stream of thoughts.
Why
When I first thought about creating TubeHound, in its earliest version, I was just unhappy with the way video hosting's search engines work. Then, I read about Meteor, and...
Reactive SVG charts with Ractive.js and Paths.js
22 Jan 2014Ractive
Ractive.js is a nice, lightweight library that allows you to easily add reactive behaviour to your web page.
It's not the first lib that allows you to use reactive programming on html markups: during the last year several of them have been released, from React to the amazing AngularJS from Google. Arguably, Angular is actually the most complete, and best maintained (no surprise, since it is a Google project!). But its many features makes it a bit heavy, and the learning curve steep. Don't get me wrong, I used Angular in a few projects (for instance, Tag Cloud) and it is awesome - especially because it allows you (or forces you) to adhere to the MVC pattern. But sometimes it is far more stuff than you'd need.
The Difference between Angular and Ractive are thoroughly addressed on Ractive's blog: mainly their scope is different, since Angular addresses also routing, validation, server communication, testing etc..., while Ractive leaves all that stuff to each developer, allowing you to choose whatever solution you like for them - if you do need them in the first place.
If you are new to Ractive, there is nothing to worry about: it is super-easy, super-useful, and there is plenty of documentation available. You might want to start here: 60 second setup
Here it is how the example in the 60 second setup would look like, assuming you downloaded the script for Ractive and saved it into the js subfolder...
Promises, noSql, joins... and more promises
18 Jan 2014Intro
Two of the top trending terms of the last couple of years in the tech world are, sure enough, promises and nosql. If you are into functional programming, the day will come that you get introduced to futures (deferred) and promises. Here is the thing: I'm not talking about Scheme or Scala; if you ever had to deal with JavaScript, you are into functional programming - if you haven't realized that yet... this is a good starting point. On the other hand, you can not possibly not have at least heard of noSql databases and call yourself a developer. Of course, they are not the answer to every problem (and we will see an example of this tradeoff in a minute), but in many situations where scalability is of the essence, they often are the best choice.
Now, you might wonder, how are these two subjects possibly related? Well, first of all, often noSql datastore servers offers asynchronous calls that either natively behaves as promises or can be wrapped into deferred to mimic promises. Redis, for example, lets you pipeline your commands (which also gives a significant performance improvement), although it forces you to use a somewhat cumbersome and odd syntax.
However, as hard as it can be to believe, I want to talk about what I think it is another contact point between the two of them: joins.
Promises
Let's take a step back, first, to briefly describe what promises and noSql DBs are. In particular,...
V-rawler, a visual extension for PyCrawler
19 Aug 2013What is it?
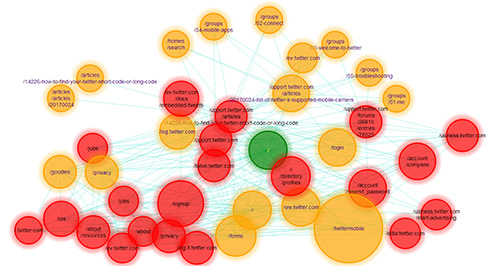
V-rawler is a visual interface for a web crawler. To put it simple, you give it a web site's URL, and it will visit it for you, creating a map of its structure, and listing the resources used by each page visited. It works with almost every single website on the net, although you might find some odd answers for a few dynamic web sites.
You can clone, fork or just take a look at its source code on its github repository.
Guide
To get started, you have 4 ways:
Visit http://v-rawler.appspot.com/ and insert the URL of the initial page to crawl in the text field of the modal dialog that appears on loading;
On the same page, after closing the dialog mentioned above, you can insert the URL in the field on the right of the navigation bar, and then hit the "Crawl" button;
A REST interface is exposed: to crawl google.com, for example, just visit http://v-rawler.appspot.com/visual/google.com; Please note that the URL used for the REST interface must NOT contain the protocol segment, i.e.: http://v-rawler.appspot.com/visual/google.com works, but http://v-rawler.appspot.com/visual/http://google.com wouldn't;
The REST interface allows you to get the json data back from the crawler, and then do whatever you want with it; for the example above, just visit http://v-rawler.appspot.com/json/google.com
Once the site has been crawled in the backend, a json object will be sent back to the client and a specific algorithm will be used to embed...
PyCrawler updated to v.1.3
16 Jul 2013PyCrawler is a simple but functional crawler written in Python, you can read the original post about it with all its features listed.
This update deals with duplicate pages: it is not uncommon that 2 different URIs lead to the same page, especially if for any reason the URLs used maintain any state info or non influential parameters (for example, without login, all the links may redirect to the home page of a web site, but that is not noticeable by looking at the URL only).
So, the solution usually enforced is to check the page content and somehow keep track of it; of course, comparing each page's content to every other page already crawled would take forever, so we need a more efficient solution: computing a digest for pages' content, and keeping the signature for each page in a hash table for constant time lookup.
Of course, two concerns still remains:
Hash tables and digest means collisions: we need to choose a digest long enough to avoid collisions as much as we can, and decide a policy to resolve them when they happens.
Computing the digest isn't free and isn't constant-time: the longest the input, the more the computation will take; the more complicated the algorithm, the slower it is.
To try to balance performance and collisions, I decided to use sha256, and to ignore collisions.
sha512 would have (probabilistically) guaranteed no collisions at all, but it would also have been much more computational intensive, slowing...