V-rawler, a visual extension for PyCrawler
What is it?
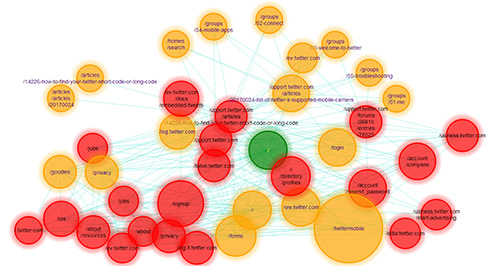
V-rawler is a visual interface for a web crawler. To put it simple, you give it a web site's URL, and it will visit it for you, creating a map of its structure, and listing the resources used by each page visited. It works with almost every single website on the net, although you might find some odd answers for a few dynamic web sites.
You can clone, fork or just take a look at its source code on its github repository.
Guide
To get started, you have 4 ways:
Visit http://v-rawler.appspot.com/ and insert the URL of the initial page to crawl in the text field of the modal dialog that appears on loading;
On the same page, after closing the dialog mentioned above, you can insert the URL in the field on the right of the navigation bar, and then hit the "Crawl" button;
A REST interface is exposed: to crawl google.com, for example, just visit http://v-rawler.appspot.com/visual/google.com; Please note that the URL used for the REST interface must NOT contain the protocol segment, i.e.: http://v-rawler.appspot.com/visual/google.com works, but http://v-rawler.appspot.com/visual/http://google.com wouldn't;
The REST interface allows you to get the json data back from the crawler, and then do whatever you want with it; for the example above, just visit http://v-rawler.appspot.com/json/google.com
Once the site has been crawled in the backend, a json object will be sent back to the client and a specific algorithm will be used to embed the map of your website on your screen, representing every page in your site with a graph vertex, a circle whose color will reflect the page's depth (how far it is from the initial page) and whose size will reflect the page's size. This algorithm works in a few steps, during which the vertex on the screen will be moved and reorganized. You can stop, pause, or cancel this process at any time using the navigation bar.
You can click on any vertex/page at any time, and this will open a dialog window with a report of the resources used by that page.
Once the embedding algorithm has or has been stopped, you can freely drag vertices around if you feel that can improve the overall embedding, or... even if you just find it fun.
If you use the left mouse button for dragging, the optimization algorithm will start again, with a storter cycle. If you, instead, use the right mouse button, the optimization algorithm will not be triggered.
Why + how
PyCrawler is a simple breadth-first, multi-thread crawler that creates a map of a single domain, returning its description as a json object. It was born as an interview challenge, and has undergone a constant tuning: it works pretty smoothly today, collecting many useful information for each website, but... if your site has more than half a dozen pages, well it becomes pretty complicated to make yourself a quick overall impression of it by looking at the json returned.
I felt that something was missing, some way to get a quick summary of your website... something visual perhaps. Being, as I am, an algorithm and graph geek, I couldn't miss this opportunity to apply one of my favourite graph embedding algorithms: GEM, an optimization algorithm based on simulated annealing which I had already used to create visual representation of Finite State Automata a few years back (well, something like 12 years back, actually...), and that was working like a charm.
Until then my algorithm was warking as a standalone Python App, which - as I was soon to discover - had greatly simplified my life thus far. Now that I had to transform it into a web application, I decided to use Google App Engine's facilities for the backend, in order to exploit their highly scalable infrastructure and hopefully not having to change a lot (how foolish of me to hope so!); for the client side, I chose a combination of the frameworks I knew best (jQuery, Bootstrap), although updated to their lates version (2 and 3 respectively), together with something I was really craving to try: Raphael.js.
I have been using D3.js for a while, also developing plugins for it; D3 is a great library indeed, but I had the feeling that Raphael would somehow overamaze me: and it actually did... overall it looks well-thought and better designed than D3, which also gave me some problems with memory management (like what looks like closure leak in the crossfiltering plugin).
Anyway, since I started its porting, I had to face a few challenges:
As I hinted above, one thing is to have your app running on your own Python interpreter, and a completely different thing is to have it running on a GAE server. First of all, multithreading: it might work on a desktop computer, but in general Python is performing better when runs on single threaded servers: the overhead for multithreading is simply too high. But, to keep me out of my dilemma, GAE simply wasn't working with Thread class: it compiled fine, it run fine crawling the pages, it allowed the locks on the shared queue to be acquired and released, but when it came to wait for the synchronized priority queue to get empty, it wouldn't trigger the expected event on queue empty, as it correctly did, instead, in the desktop app version. There was no way to have it working, so the simplest thing to do was simply... remove the multithread mechanism, and dumb it down to a single threaded crawler. This means that, if the slowest page to load is crawled first, no other page will be crawled in the meantime. To alleviate this behaviour, pages that aren't loaded within 5 seconds are simply discarded.
As I was just saying, time is critical. Especially since GAE instances aren't allowed to run for more than 60 seconds, no matter what :-/ That meant that I had to cut down the maximum number of pages crawled by the app: I had set a limit to a reasonable 50, but I had to go as down as 30 to avoid timeout errors. If anybody from GAE reads this... please, do something about this, 'cause it's really frustrating! I realize that it is true what the guys at Udacity where saying: GAE is really amazing, but it can be a nightmare if you want to do something different from what their creators thought you should do.
urlopen. Simply doesn't work. I needed to switch to GAE API's urlfetch, which basically does the same job, but with a different interface, and works only on Google App Engine.
How could I avoid v-rawler to be used for DoS (Denial of Service) attacks? Well, first I put an object cache (Memcached, luckily built-in into GAE) in front of my application, so that most common searches are stored into this cache, and the app avoid crawling the website again, giving both better security and a faster response time. Then I also added a second security measure: a single IP address is allowed to make a single search every 10 seconds, initially. If two searches are performed in less than twice this interval, the interval itself doubles, and the next time 20 seconds will be necessary; the more searches are made, the longer will become the interval.
With traffic increasing on the website, the number of IP entries to store on the DB will be raising dramatically. Most of them, however, will be useless: we just need to keep track of the last search from an IP address if it has happened within the last 10 seconds (or whatever the interval has become for that IP). Every older information is redundant, so a cron job will erase it from the DB, cleaning it several times each day.
On the client side, the most difficult challenge was getting rid of closure memory leaks: since every page is represented with one (actually, more than one, but considering them as one is a good abstraction) interactive SVG element, with event handlers for click, drag, mouseover and mouseout events, each one of this functions had initially in its closure a var to keep track of its target, plus all the variables declared in the drawing function, including a (big!) array containing all the graph's vertices. A first optimization was obtained by creating parametric generators for this event handlers: ironically, using closures again, and moving this generators out of the drawing function, at least 2 to 5 megabytes are saved for every search.
To have a further optimization, I exploited the bubbling nature of event handling in JavaScript: a Raphael set element was created and every SVG element representing a vertex was inserted into this set; then the event handlers for the 5 events above were added only once for each event to the set instead that n times to the each of the n vertices.